Paper · 8–10 min read · 2026-06-11
SWE-Lego: Pushing the Limits of Supervised Fine-Tuning for Software Issue Resolving
A close read of the paper behind the pipeline — and why a careful SFT-only recipe still sets the pace for open issue-resolving models. arXiv:2601.01426.
Most of the recent progress on autonomous software engineering — agents that read a bug report, navigate a repository, edit code, and run tests until the suite goes green — has come wrapped in elaborate training stacks: a round of supervised fine-tuning, then reward modeling, then one or more rounds of reinforcement learning, each with its own infrastructure and failure modes. SWE-Lego asks a deliberately unfashionable question: how far can you get with supervised fine-tuning alone, if you do every part of it carefully?
The answer, it turns out, is far. On SWE-bench Verified — the human-filtered slice of SWE-bench where every task has a known-good patch and a reliable test — an 8B model trained with the SWE-Lego recipe resolves 42.2% of issues on its own, rising to 49.6% with test-time scaling. The 32B model reaches 52.6%, and 58.8% once you let it think across sixteen candidate solutions. Those are state-of-the-art numbers among open models of comparable size, reached without a single step of RL.
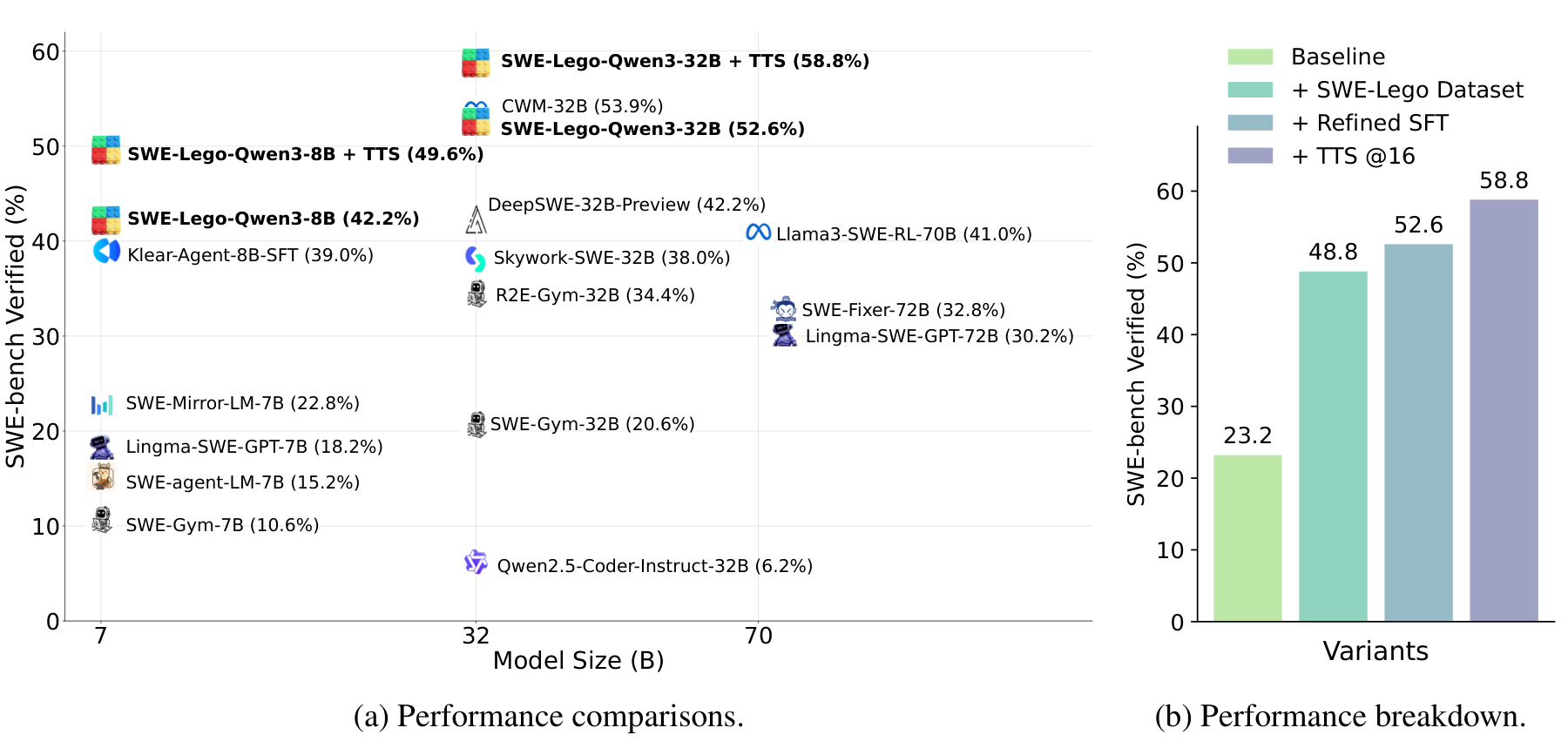
This is the paper that motivates LegoFactory. The pipeline you see on the rest of this site — instance collection, trajectory rollout, SFT, evaluation — is the productionized, agent-operated form of the recipe described below. So it is worth understanding what the recipe actually is.
The bet: SFT is data-bound, not method-bound
The implicit claim behind a complex RL stack is that supervised learning has been wrung dry — that to go further you need a reward signal and on-policy exploration. SWE-Lego pushes back on this. Its position is that the ceiling people hit with SFT is usually a data ceiling and a loss ceiling, not a fundamental limit of the paradigm. Fix what the model is trained on, and fix which tokens it is asked to imitate, and the supervised baseline moves a long way up before RL ever enters the picture.
Concretely, the recipe rests on three building blocks: a curated dataset, a refined training procedure, and a test-time scaling stage. Each is simple in isolation; the result comes from getting all three right at once.
Building block 1 — Data that is real, varied, and verified
The dataset pairs two kinds of supervision. The first is task instances: roughly 32,000 of them, drawn from over 3,000 real repositories and filtered for the properties that make a task usable for training — a clear problem statement, a runnable environment, and tests that actually discriminate a correct fix from a broken one. The second is trajectories: about 18,000 full agent rollouts — the sequences of thoughts, tool calls, file edits, and test runs that carry a task from its initial broken state to a passing one.
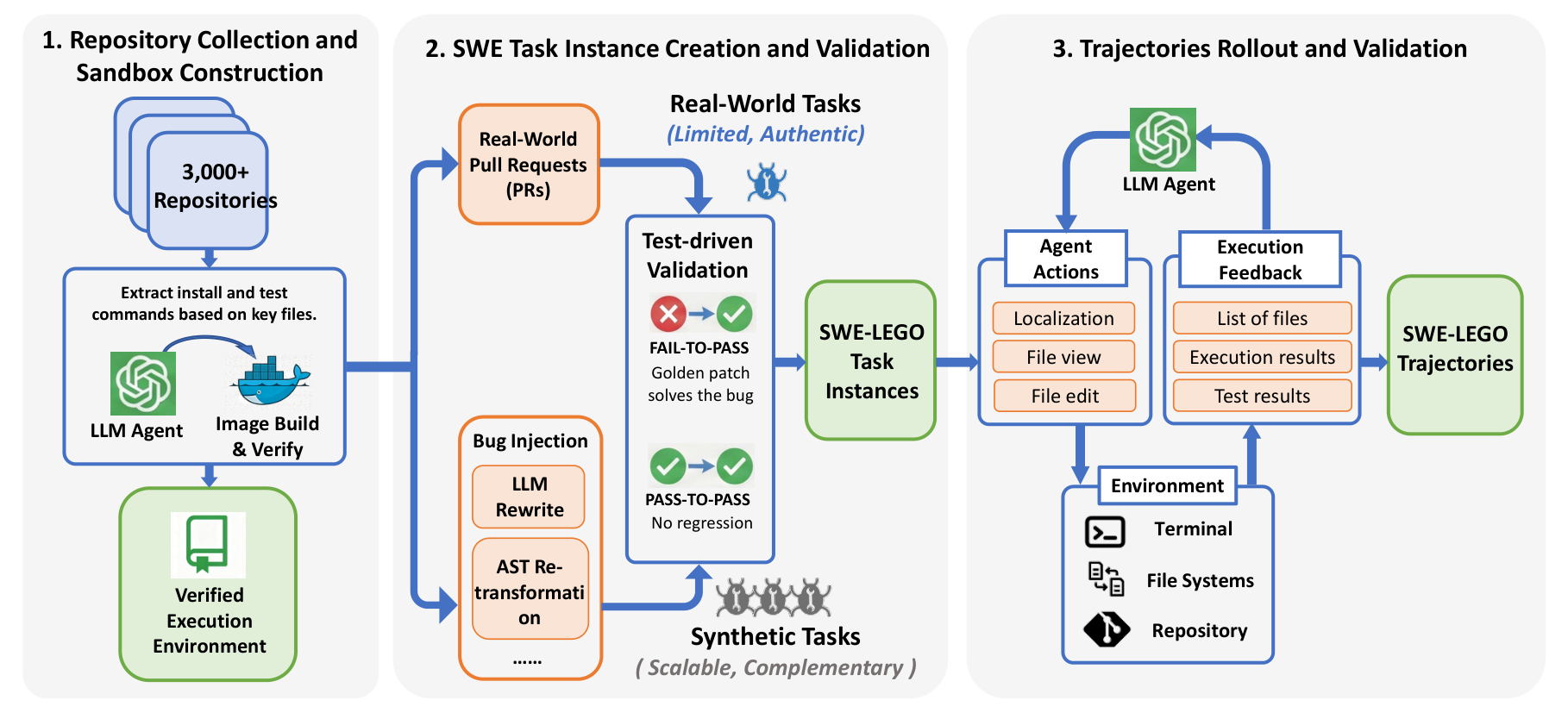
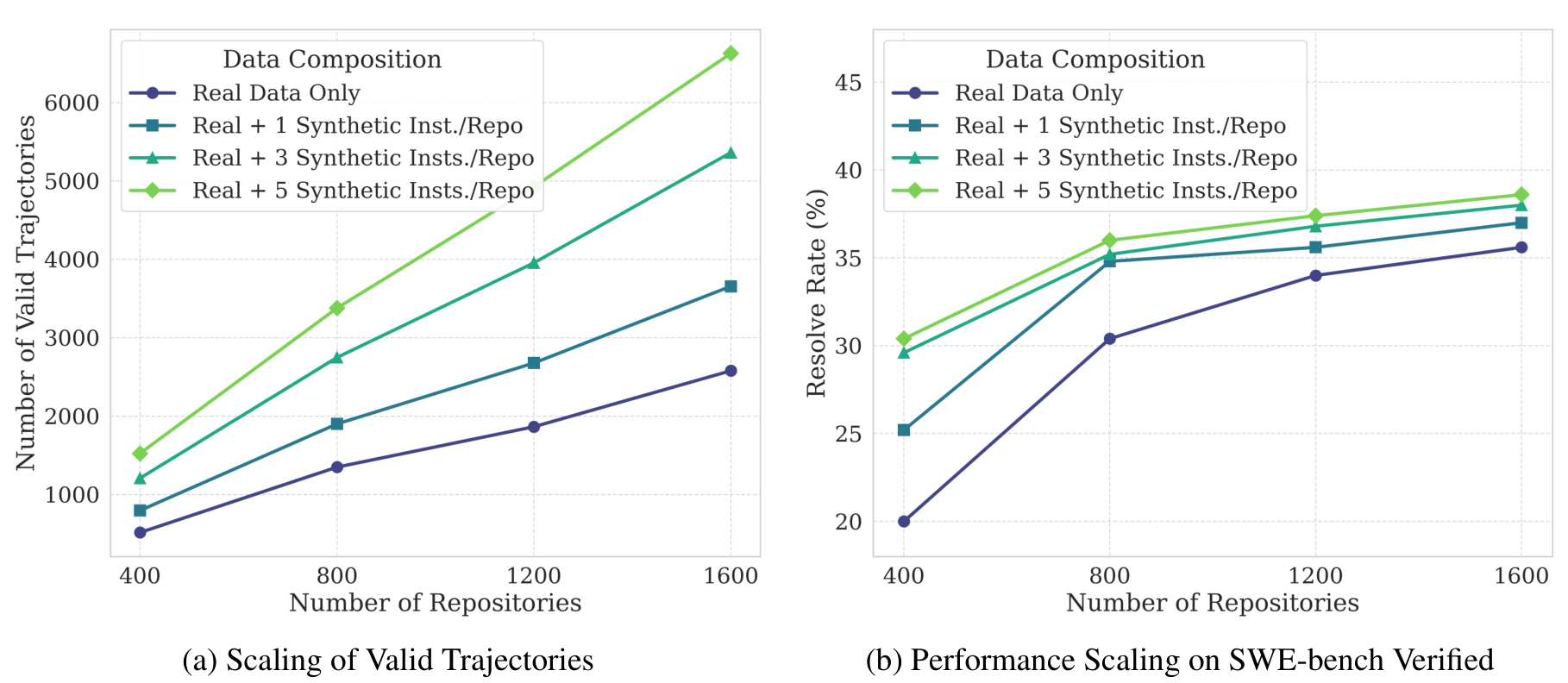
swegen and trajgen.Two design choices matter here. First, the data mixes real and synthetic sources rather than betting on either alone: real issues bring the messy distribution of actual software work, while synthetic generation — bug injection, LLM rewrites, AST re-transformation — fills in coverage where naturally occurring data is thin. The payoff is concrete: adding synthetic instances per repository scales the volume of valid trajectories and steadily lifts resolve rate.
Second — and this is the part LegoFactory takes most seriously — the trajectories are validated, not merely collected. A trajectory only earns its place if it genuinely resolves the task: the edits apply, the previously failing tests pass (FAIL-TO-PASS), and the previously passing tests stay passing (PASS-TO-PASS). Unverified trajectories are exactly the kind of plausible-but-wrong supervision that quietly teaches a model bad habits, and the recipe refuses to pay that cost. This is why LegoFactory’s swegen stage only keeps tasks that pass a NOP/Oracle check, and trajgen only keeps trajectories that actually succeed.
Building block 2 — Training that respects what went wrong
Given good data, the question becomes how to learn from it. A naïve SFT run treats every token in every kept trajectory as something to imitate. SWE-Lego refines this in two ways.
Error masking
Even a trajectory that ultimately succeeds is rarely clean. The agent takes a wrong turn, runs a command that fails, edits the wrong file, backtracks, and only then converges. If you train on the raw sequence, you teach the model the recovery and the mistake that made recovery necessary. Error masking addresses this by withholding the training loss from the actions that represent missteps, while keeping the full trajectory in context — so the gradient flows through the parts worth imitating and not through the dead ends.
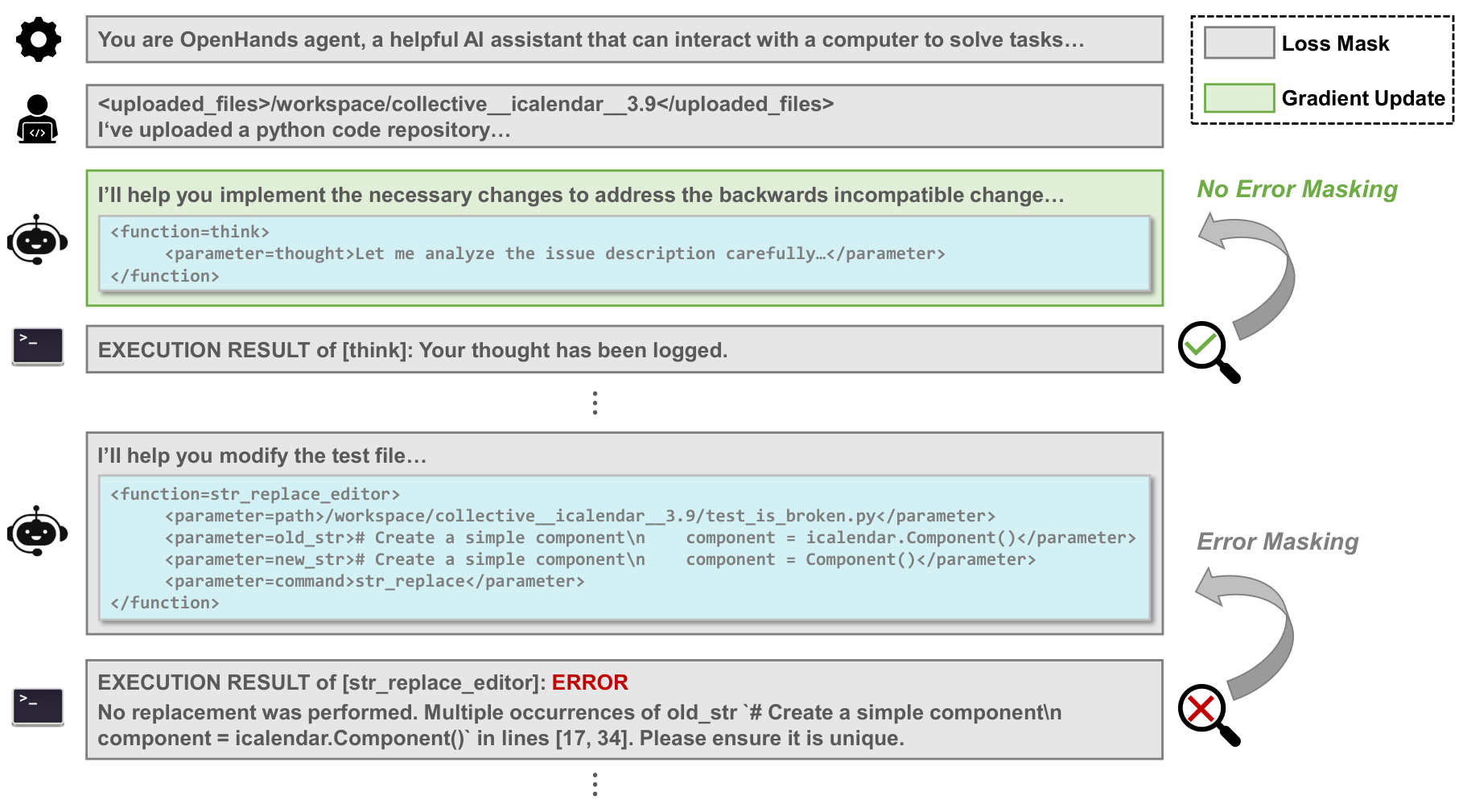
str_replace), so the model imitates the recovery, not the misstep.Difficulty-based curriculum
Not all of the 18k trajectories are equally hard to learn from. SWE-Lego orders training by difficulty — using trajectory length as a proxy in a multi-stage curriculum — letting the model consolidate the mechanics of issue resolving on easier instances before being asked to fit the long, branching trajectories that hard tasks produce. In the ablations, dropping either error masking or curriculum learning costs resolve rate on both the 8B and 32B models, and dropping both costs the most.
Building block 3 — Spending compute at test time
The third block is where the largest single jump in the headline numbers comes from. After fine-tuning, SWE-Lego trains a verifier — a model whose job is not to solve the task but to judge candidate solutions. At inference, the policy samples several attempts at a given issue; the verifier scores them; the best-scoring candidate is submitted. This is the meaning of TTS@k: test-time scaling with k sampled candidates.
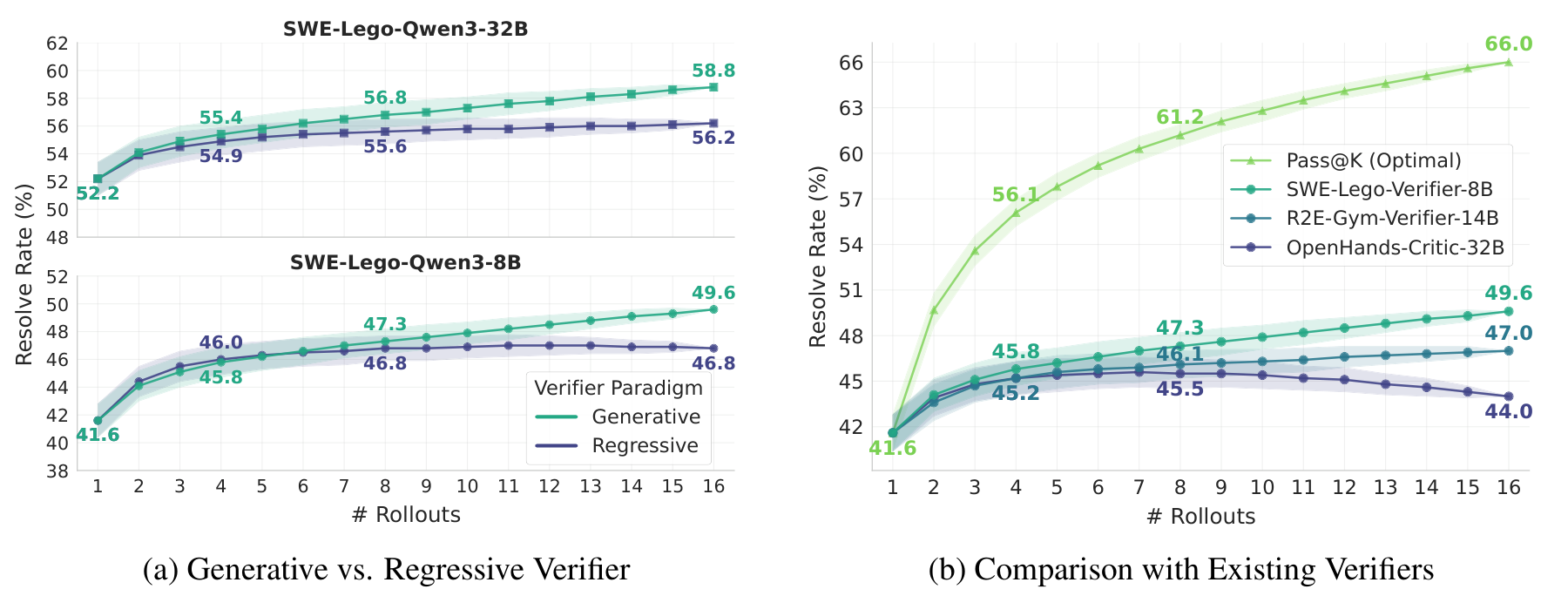
The gains are substantial and consistent across model sizes. For the 8B model, test-time scaling lifts resolution from 42.2% to 49.6%. For the 32B model, TTS@16 lifts it from 52.6% to 58.8%. The intuition is that a well-trained policy already contains a correct solution among its samples more often than it manages to produce one on the first try — so the bottleneck shifts from generation to selection, and a good verifier is a cheap way to buy back that gap. The paper also finds a generative verifier (predict “yes/no”, then reason) outperforms a regressive one, and that the best strategy is sequential-then-parallel.
The numbers, in one place
On SWE-bench Verified:
- SWE-Lego-Qwen3-8B — 42.2% base → 49.6% with test-time scaling.
- SWE-Lego-Qwen3-32B — 52.6% base → 58.8% at TTS@16.
Both are competitive with, or ahead of, open models in their size class — and both are reached with supervised fine-tuning plus a verifier, no reinforcement learning in the loop. That is the paper’s central, slightly provocative point: a large fraction of what people reach for RL to obtain is recoverable from better data, a more careful loss, and a modest amount of test-time search.
What it means for LegoFactory
A recipe is only as repeatable as the pipeline that feeds it. The reason SWE-Lego’s data story translates into LegoFactory is that every ingredient the paper relies on maps onto a stage you can run:
- Instance collection produces the verified, test-backed task instances — the 32k.
- Trajectory rollout generates and validates the agent trajectories — the 18k.
- SFT applies error masking and the difficulty curriculum on top of that data.
- Evaluation closes the loop on SWE-bench Verified and feeds the verifier that powers test-time scaling.
The paper shows that this sequence, done carefully once, reaches the state of the art. LegoFactory’s bet is that the more valuable property is being able to do it continuously — to keep collecting fresh instances as repositories evolve, keep validating trajectories, and keep retraining — without a human re-wiring the pipeline each time. That is what the block-wise, agent-operated design is for: every stage above is a self-contained block with a contract, so the whole recipe composes, and re-runs, like Lego.
If you want the full method and ablations, read the paper: SWE-Lego (arXiv:2601.01426). If you want to run the pipeline that produces this kind of data, start with the docs.