Paper · 8–10 min read · 2026-06-12
What Makes Interaction Trajectories Effective for Training Terminal Agents?
The strongest agent is not the best teacher. Why environment grounding — not raw teacher skill — decides what a student learns. arXiv:2606.03461.
Here is the assumption almost everyone makes when distilling agent trajectories: pick the best agent you can afford as the teacher, have it solve a pile of tasks, and fine-tune your student on what it did. A stronger teacher should mean a stronger student. This paper shows that assumption is not just imperfect — it can be backwards.
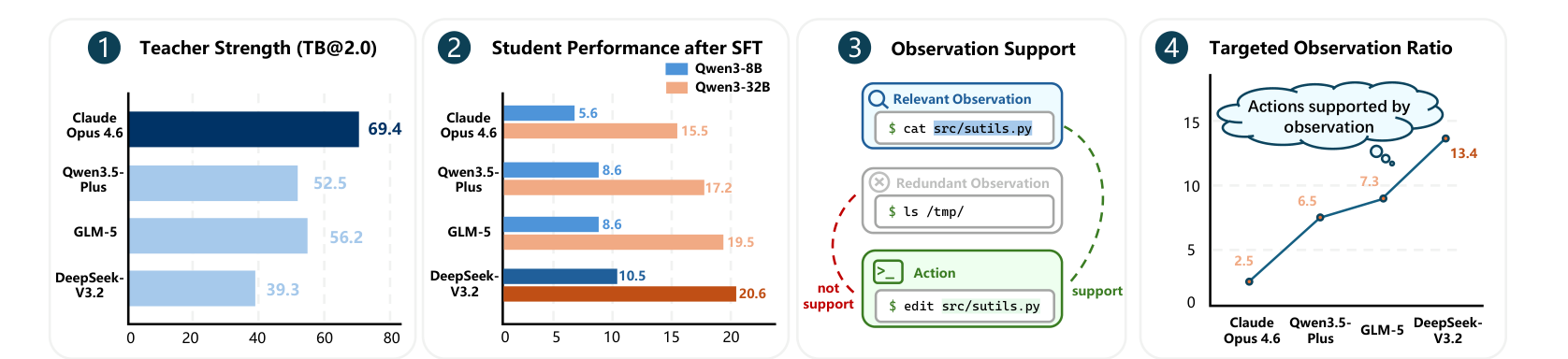
On Terminal-Bench 2.0, Claude Opus 4.6 scores 69.4 — the strongest teacher in the study. DeepSeek-V3.2 scores 39.3, the weakest. But fine-tune Qwen3-8B and Qwen3-32B on each teacher’s trajectories and the ranking inverts: the DeepSeek-trained students reach 10.5 and 20.6, while the Claude-trained students manage only 5.6 and 15.5. The best solver is the worst teacher. The paper calls this the pedagogical paradox, and most of the work is about explaining it.
What actually transfers: environment grounding
The instinctive explanations don’t survive contact with the ablations. It isn’t trajectory length — the authors show that taking DeepSeek’s longest successful trajectories doesn’t help, and can hurt. It isn’t explicit error recovery either. And it isn’t imitation difficulty in the obvious direction: Claude’s trajectories have the lowest training loss and are the easiest to fit, yet they transfer the worst. Strikingly, even failed DeepSeek trajectories — runs that never solved the task — still teach a usable student.
What separates the good teachers from the bad ones is Environment-Grounded Supervision (EGS): trajectories that visibly inspect, act, and verify through the harness. A grounded step reads the relevant state (cat src/utils.py), takes an action conditioned on what it just saw (edit src/utils.py), and then confirms the effect. A strong model like Claude often skips the visible inspection — it “just knows” the answer and emits the action — so its trajectory is a sequence of correct moves with the reasoning grounded in the model’s weights rather than in the environment. A student imitating that learns to memorize action sequences. A student imitating a grounded trajectory learns the loop — look, decide, check — which is what generalizes to new tasks.
The paper makes this measurable with the Targeted Observation Ratio (TOR): the fraction of actions that are supported by a relevant prior observation. DeepSeek-V3.2 has the highest TOR (13.4 in Figure 1’s units); Claude Opus 4.6 the lowest (2.5). Student performance tracks TOR, not teacher strength — which is the whole paradox in one number.
Terminal-Lego: a controlled substrate for the study
To test this cleanly you need many tasks that are real, varied, and automatically verifiable — so that the only thing changing between experiments is the teacher. That substrate is Terminal-Lego, a pipeline that turns real Stack Overflow problems into sandboxed, test-backed terminal tasks.
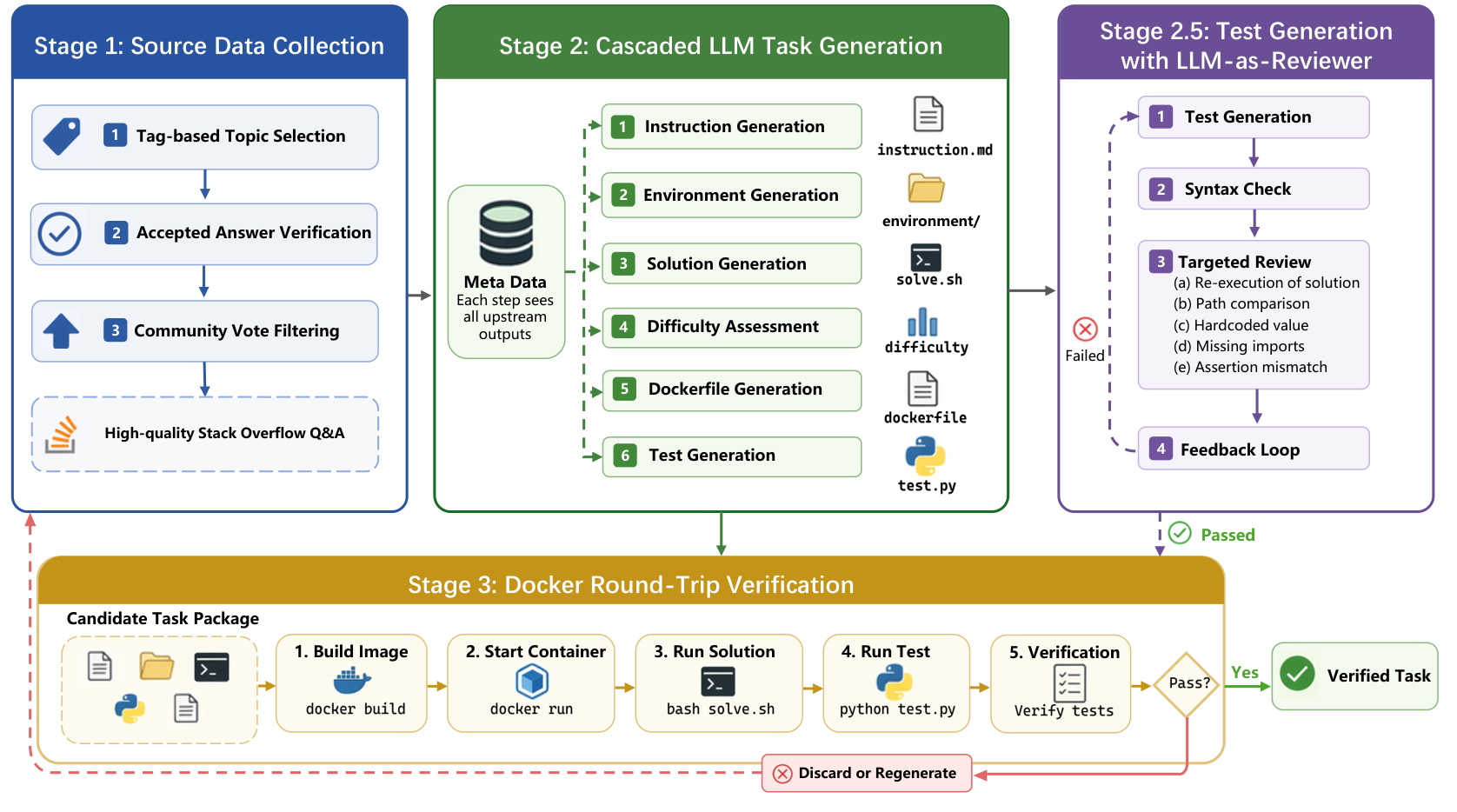
The shape will look familiar if you’ve read the SWE-Lego post: a collection stage that mines real sources, a generation stage that cascades structured artifacts, and a round-trip verification stage that builds a Docker image, runs the reference solution, runs the tests, and discards anything that doesn’t pass. Tasks are kept only when the environment confirms them — the same fail-to-pass / pass-to-pass discipline, applied to terminal work instead of repository PRs.
The efficiency payoff
Grounding isn’t only a quality story; it’s an efficiency story. Because environment-grounded trajectories teach the loop rather than the answer, you need far fewer of them. With only 15.3k Terminal-Lego trajectories, Qwen3-32B reaches 24.3% on Terminal-Bench 2.0 — matching results that previously took on the order of 30× more data. Selecting for grounding does more than scaling the pile.
Harness engineering, not outcome matching
The authors frame the takeaway as a shift from outcome matching — collect trajectories that reached the goal — to harness engineering: deliberately designing the interaction structure so that the visible trace contains inspect-act-verify behavior worth imitating. The teacher’s job is not to be the best solver; it’s to leave behind a trace that grounds every action in something the environment showed it.
What it means for LegoFactory
This lands directly on LegoFactory’s trajectory-rollout stage. The obvious move — roll out the strongest available model and keep whatever solves the task — is exactly the move this paper warns against. Two concrete implications:
- Select trajectories by grounding, not just success. A metric like TOR is a cheap, harness-visible filter that predicts teaching value — and even some failed runs are worth keeping.
- Engineer the harness so grounding is forced. Scaffolds that require an inspection before an edit produce traces that transfer — the rollout block is where that choice is made.
It also reinforces why a pipeline beats a one-off distillation run: the right teacher and the right harness are empirical questions, and you only answer them by collecting, training, and evaluating in a loop you can re-run. That is the block LegoFactory is built to turn.
Full method, ablations, and command-level analysis are in the paper: arXiv:2606.03461. To run the data pipeline this thinking informs, start with the docs.